




As a member of the team responsible for keeping ProPublica’s website online, there were times when I wished our site were static. Static sites have a simpler configuration with fewer moving parts between the requester and the requested webpage. All else being equal, a static site can handle more traffic than a dynamic one, and it is more stable and performant. However, there is a reason most sites today, including ProPublica’s, are dynamically generated.
In dynamic sites, the structure of a webpage — which includes items such as titles, bylines, article bodies, etc. — is abstracted into a template, and the specific data for each page is stored in a database. When requested by a web browser or other end client, a server-side language can then dynamically generate many different webpages with the same structure but different content. This is how frameworks like Ruby on Rails and Django, as well as content management systems like WordPress, work.
That dynamism comes at a cost. Instead of just HTML files and a simple web server, a dynamic site needs a database to hold its content. And while a server for a static site responds to incoming requests by simply fetching existing HTML files, a dynamic site’s server has the additional job of generating those files from scripts, templates and a database. With moderately high levels of traffic, this can become resource intensive and, consequently, expensive.
This is where caching comes into play. At its most basic, caching is the act of saving a copy of the output of a process. For example, your web browser caches images and scripts of sites you visit so subsequent visits to the same page will load much faster. By using locally cached assets, the web browser avoids the slow, resource-intensive process of downloading them again.
Caching is also employed by dynamic sites in the webpage generation process: at the database layer for caching the results of queries; in the content management system for caching partial or whole webpages; and by using a “reverse proxy,” which sits between the internet and a web server to cache entire webpages. (A proxy server can be used as an intermediary for requests originating from a client, like a browser. A reverse proxy server is used as an intermediary for traffic to and from a server.)
However, even with these caching layers, the demands of a dynamically generated site can prove high.
This was the case two years ago, shortly after we migrated ProPublica’s website to a new content management system. Our new CMS allowed for a better experience both for members of our production team, who create and update our articles, and for our designers and developers, who craft the end-user experience of the site. However, those improvements came at a cost. More complex pages, or pages requested very frequently, could tax the site to the point of making it crash. As a workaround we began saving fully rendered copies of resource-intensive pages and rerouting traffic to them. Everything else was still served by our CMS.
As we built tools to support this, our team was also having conversations about improving platform performance and stability. We kept coming back to the idea of using a static site generator. As the name suggests, a static site generator does for an entire site what our workaround did for resource-intensive pages. That is, generate and save a copy of each page. It can be thought of as a kind of cache, saving our servers the work of responding to requests in real time. It also provides security benefits, reducing a website’s attack surface by minimizing the amount users interact directly with potentially vulnerable server-side scripts.
In 2018, we brought the idea to a digital agency, Happy Cog, and began to workshop solutions. Because performance was important to us, they proposed that we use distributed serverless technologies like Cloudflare Workers or AWS Lambda@Edge to create a new kind of caching layer in front of our site. Over the coming months, we designed and implemented that caching layer, which we affectionately refer to as “The Baconator.” (Developers often refer to generating a static page as “baking a page out.” So naturally, the tool we created to do this programmatically for the entire site took on the moniker “The Baconator.”) While the tool isn’t exactly a static site generator, it has given us many of the benefits of one, while allowing us to retain the production and development workflows we love in our CMS.
How Does It Work?
There are five core components:
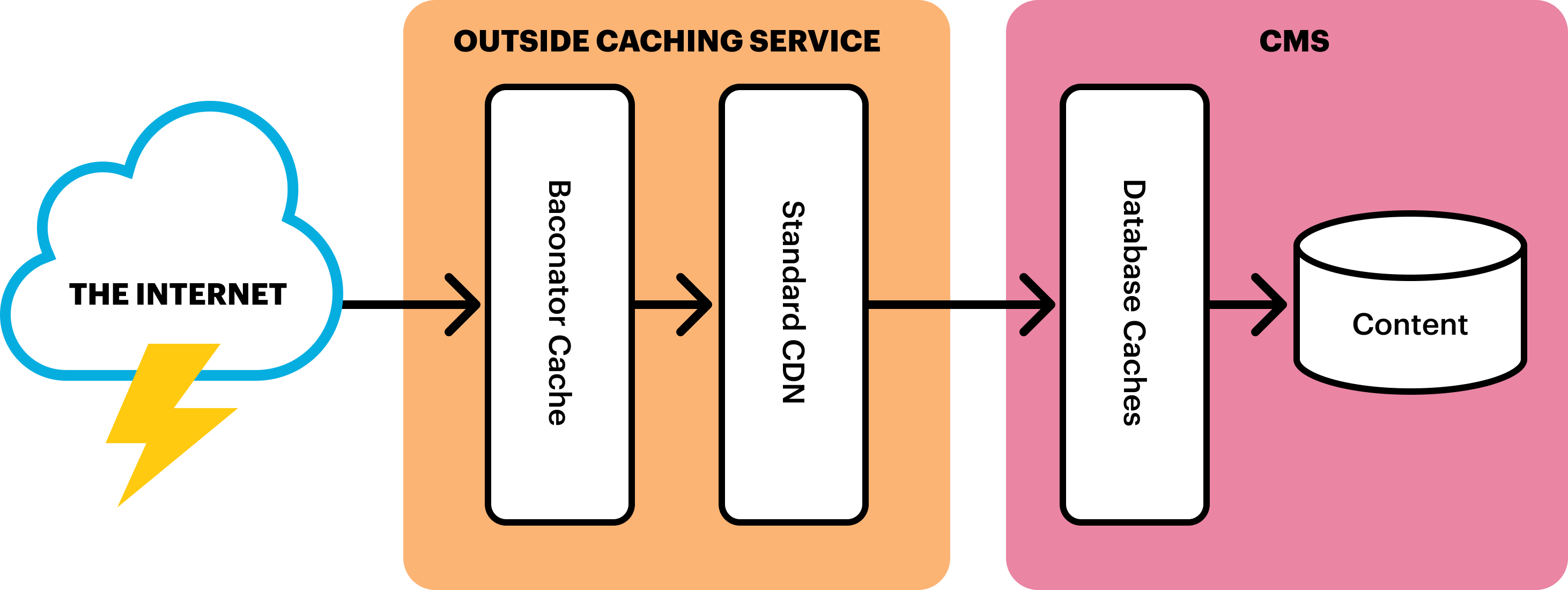
- Cache Data Store: A place to store cached pages. This can be a file system, database or in-memory data store like Redis or Memcached, etc.
- Source of Truth (or Origin): A CMS, web framework or “thing which makes webpages” to start with. In other words, the original source of the content we’ll be caching.
- Reverse Proxy: A lightweight web server to receive and respond to incoming requests. There are a number of lightweight but powerful tools that can play this role, such as AWS Lambda or Cloudflare Workers. However, the same can be achieved with Apache or Nginx and some light scripting.
- Queue: A queue to hold pending requests for cache regeneration. This could be as simple as a table in a database.
- Queue Worker: A daemon to process pending queue requests. Here again, “serverless” technologies, like Google Cloud, could be employed. However, a simple script on a cron could do the trick as well.
How Do the Components Interact?
When a resource (like a webpage) is requested, the reverse proxy receives the request and will then check the cache data store. If the cache for that resource exists, its expiration, or time to live (TTL), is saved in a variable to check against later, and the cache is served. The TTL is then checked. If the cache has not yet expired for the resource, it is considered valid and nothing else is done. If the cache has expired, the reverse proxy then adds a request to the queue for that resource’s cache to be updated.
Meanwhile, the queue worker is constantly checking the queue. As requests come into the queue, it generates the webpage from the origin and updates the corresponding cache in the data store.
And finally at the origin, anytime a page is created or edited, the cache data store is amended or updated.
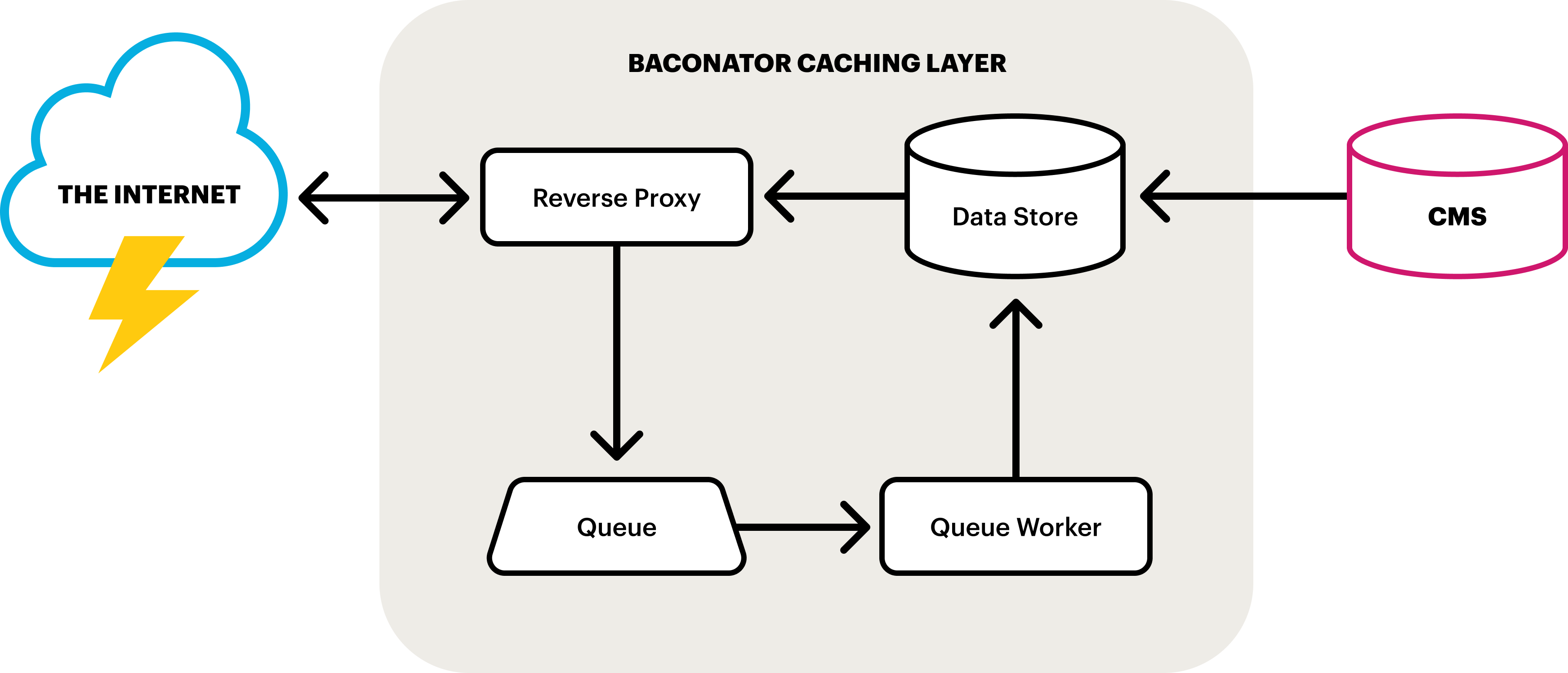
For our team, the chief benefit of this system is the separation between our origin and web servers. Where previously the servers that housed our CMS (the origin) also responded to a percentage of incoming requests from the internet, now the two functions are completely separate. Our origin servers are only tasked with creating and updating content, and the reverse proxy is our web server that focuses solely on responding to requests. As a consequence, our origin servers could be offline and completely inaccessible, but our site would remain available, served by the reverse proxy from the content in our cache. In this scenario, we would be unable to update or create new pages, but our site would stay live. Moreover, because the web server simply retrieves and serves resources, and does not generate them, the site can handle more traffic and is more stable and performant.
Read More

Another important reason for moving to this caching system was to ease the burden on our origin servers. However, it should be noted that even with this caching layer it is possible to overload origin servers with too much traffic, though it’s far less likely. Remember, the reverse proxy will add expired pages to the queue, so if the cache TTLs are too short the queue will grow. And if the queue worker is configured to be too aggressive, the origin servers could be inundated with more traffic than they can handle. Conversely, if the queue worker does not run frequently enough, the queue will stay high, and stale pages will remain in cache and be served to end users for longer than desired.
The key to this system (as with any caching system) is proper configuration of TTLs: long enough so that the queue stays relatively low and the origin servers are not overwhelmed, but short enough to limit the time stale content is in cache. This will likely be different for different kinds of content (e.g., listing pages that change more frequently may need shorter TTLs than article pages). In our implementation, this has been the biggest challenge with moving to this system. It’s taken some time to get this right, and we continue to tweak our configurations to find the right balance.
For those interested in this kind of caching system, we’ve built a simple open-source version that you can run on your own computer. You can use it to explore the ideas outlined above.









