



On Tuesday we published a graphic that looks at six variations of a single email sent out by the Obama re-election campaign last Thursday night.
This all started when fellow news nerd Dan Sinker got an email from the campaign on the same night his wife did and noticed that although they were both apparently from the same person at the campaign — Julianna Smoot — the e-mails had subtle differences. So Dan set up a Google form and asked his Twitter followers to send in their own examples of the “Smoot Email.”
At ProPublica, we’d been wanting to dig more deeply into how “big campaign data” works so we struck a deal with Dan: He’d share his database with us and we’d help analyze and visualize it.
Of course, it was far from a valid sample, but we thought analyzing the data would yield interesting observations if not statistically significant conclusions.
Preprocessing
We found six “clusters” in the 190 emails by grouping the emails using a statistical formula called the Pearson Correlation. More on that in a second.
In order to combat changes in whitespace or accidental insertions or deletions in the emails from influencing comparisons, we used a process called “stemming” to reduce each word to a common prefix. For example the stemmer we used changes the word “writing” into “write” and “journalism” into “journal”. Then we removed common words like “and”, “or”, and “but” from each email.
Finally, we translated each document into a list of word frequencies, which converted each email into an abstract representation called a “bag of words” — like this:
"curious" => 1.0,
"elig" => 1.0,
"told" => 1.0,
"payment" => 3.0
Stemming, Bagging and Correlating
By treating each email as a “bag of words”, we were able to use the Pearson Correlation to group them together with others in the set.
In statistics, the Pearson Correlation describes the strength of the dependence between two variables. In other words, it is a measure of how two variables change with one another. It returns a value from -1 to 1, with 0 meaning no correlation and 1 meaning perfect positive correlation and -1 meaning perfect inverse correlation. The Pearson Correlation wikipedia page explains the math behind the formula.
To determine whether a document belonged to a group or not, we set the threshold at 0.85.
After running the stemming, bagging and correlating we found that our sample contained six distinct emails.
Diffing and Visualizing
As it turns out the problem of computing differences between documents is very well understood, although it’s quite complex. Rather than implementing our own version of the algorithm, we used one written by John Resig, the creator of jQuery.
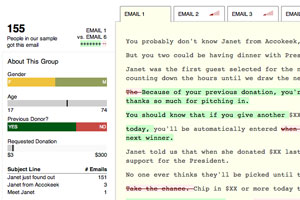
Because the emails ranged from very similar to quite different, we wanted an interface that made the variability easy to see at a glance. In addition to a small graphical indicator in the tabs that lets a reader know how strongly other emails match the one inside the tab, a reader can hover over each tab and compare emails very quickly.
In order to keep track of everything client-side, we modeled the data as an array of arrays. We wrote a small table-based javascript framework to do so, which turned out surprisingly like our Ruby-based library table-fu. You can check out the source over on github.
That JavaScript code — we’re calling it table.js — is really easy to use. You can call the regular functional programming methods — each, map, reduce — on each table. It also has simple statistics built in. For example:
var table = new Table([["one", "two", "three"], [4,5,6], [7,8,9], [10, 11, 12]]);
table.stdev("two");
=> 2.449489742783178
table.average("two");
=> 8
table.sum("two");
=> 24
Table.js also allowed us to build out the sidebar which shows a simple breakdown of the recipients of each email. Because HTML is really good at displaying rectangles, the graphs in the sidebar are built entirely out of carefully positioned divs.
Correction: This post originally stated that a Pearson Correlation score
of -1 meant no correlation, in fact a score of 0 means no correlation, and a score
of -1 means negative correlation. The post has been updated to reflect this fact.









