
Last week we published The Opportunity Gap, a news application that lets readers find out how equally their state provides poor and wealthier schools access to advanced classes that researchers say will help students later in life.
It features a host of technologies we’re using for the first time and that we anticipate will be part of many of our news apps in the future. These include a new JavaScript-based “workspace” approach to placing, sorting and removing multiple entities on a single page. We also built our own map server, which we’ll have lots to say about later this summer.
We designed the app so it was oriented behaviorally and not just hierarchically. That is, rather than simply showing users a collection of items (as so many interactive databases do), we wanted to encourage people to take the conversations they were already having about their schools and communities and extend that behavior onto our app. We owe a debt to Nick Disabato, whose SXSW talk [ZIP file of slides] really got us thinking about this concept. We were also inspired by the New York Times’ Oscars app, which uses Facebook to let readers create, share and compare their ballots with friends, and to let them reproduce real-world behavior—competing on Oscar predictions—within a news app.
This emphasis on encouraging behavior—coupled with our preference for keeping our apps light on database writes—spurred us to integrate Facebook in a deeper way than we’ve done before.
Our Facebook integration took four main shapes:
-
As an identity provider—users can log into the app using their Facebook login, eliminating the need for us to build our own authentication scheme.
-
As a way for readers to share the personal stories they’ve found in our very large data set.
-
As a relevance engine that shows readers schools that may interest them by looking at (with permission) their Facebook interests, and at whether their friends have logged in.
-
As a trusted database of user data that stores and sanitizes data and content and allows us to keep our app fully cached.
Identity and sharing are Facebook’s bread and butter—every developer who uses Facebook Connect probably starts with these. You even get much of this functionality with Facebook’s out-of-the-box social plugins. But some of the other ways we used Facebook might not be as obvious:
Facebook As a Relevance Engine
We think one of the coolest features of this app is that it attempts to show readers the schools they care about even before they search for them. We use Facebook to do this. It’s the reason we ask for so many Facebook permissions (like education history) when readers connect.
When a reader logs in and grants ProPublica access, the app digs through their profile looking for their education history, groups and likes, and tries to find a match with a school in our database. If it finds one, it shows the school a reader went to or that they care about right on the main page.
In order to make this work, we first had to build a database of Facebook IDs associated with schools. We ran each of the 55,000 schools in our database through Facebook’s search API to find relevant pages. Because each school might have many pages and groups associated, we ended up with over 2 million Facebook page IDs in our database, which our app queries to try to match schools to a reader’s profile.

We couldn’t reach 100 percent accuracy because of the way Facebook categorizes school pages. We found school pages filed under everything from “organization” to “local business.” Also, there were rarely official pages for each school. So, searching for “Kenwood Academy High School” might not return the “Kenwood Academy” page, which, with the largest number of members, is probably the one we want.
Another way we use Facebook as a relevance engine is to show a reader which of their friends have compared schools using the app. So, we show schools that matter to a reader because of their own educational history and that matter to a reader because it matters to their friends and family.

We hope that by adding personalization to the standard browse/search interface we’re giving readers a deeper connection to the data and lighting pathways to readers own stories.
A ‘Database’ Built for Sharing
Once a reader has found their school, we wanted to encourage them to compare that school with other schools—after all, the story we’re trying to tell is about equal access to advanced classes—and to share their findings with others. But as a rule we try to avoid building apps that need to store and display reader-generated data (because it makes scaling much harder, and can create security pitfalls), so simply writing comparisons and comments to a local database was, for us, suboptimal.
So, we used Facebook to power this part of the app. Using Facebook’s very expressive JavaScript SDK, our app combines the schools a reader has collected, the sort order the reader specified (such as Advanced Placement enrollment), along with an optional comment, into a single URL that a reader can share via Twitter, email and their Facebook wall. We didn’t need to build our own commenting interface because Facebook already has the infrastructure to allow editing and deleting of user content. We just proxy that to our app.
This approach came with a few challenges. We had to work within Facebook’s permissions model. Anything a reader shared needed to behave like a wall post and obey that reader’s privacy settings. And for obvious reasons we needed to be sure that the requests to create new URLs on our site were actually coming from the same Facebook user that logged in.
Our solution actually lets us avoid entirely serving reader-generated data directly from an internal database. We rely heavily on Facebook’s JavaScript SDK and simply sling post IDs and user IDs. Via API calls, we create a wall post, confirm that it’s from the user we expected and then pull it back from Facebook and display it along with the sorted comparison.
Here’s what it looks like when a reader creates (and then views) a comparison:
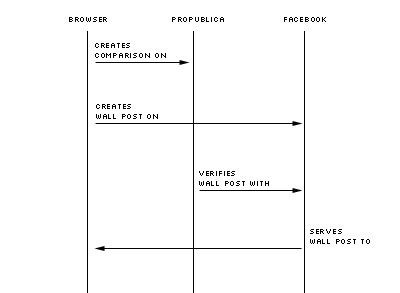
Because we have stashed the Facebook wall post ID the web browser retrieves the reader comment directly from Facebook via the API, and not from our database. And because we’re never actually grabbing the comment from a local database, we are protected from malicious code (posts are sanitized by Facebook), and we are still operating safely within Facebook’s privacy requirements. If the reader who is making the comparison has their wall set to “friends only,” then only that reader’s friends will see the comment in our app, otherwise the comparison shows up as from an anonymous reader and with no comment. And if a user deletes their wall post, it’s also “deleted” on our comparison page, without our app having to do anything.
So, here’s how one comparison post might look to three different users:

Facebook played a key role as both an identity provider and a database of sorts in “The Opportunity Gap.” We’ve already got plans for what we’re going to be doing next with what we’ve learned. You’ll be seeing similar integrations in our future projects.
Our thanks to Vadim Lavrusik and Nick Grudin at Facebook for looking at early drafts of the app and advising us on optimizing the experience for our readers.






