
A few days ago, the RAND Corporation published an opinion piece that raised questions about Surgeon Scorecard, our searchable online database of complication rates for surgeons performing several elective operations. We appreciate the authors’ intentions and plan to take some suggestions into account as we prepare Surgeon Scorecard 2.0.
We do, however, disagree with much of what is argued in the RAND essay. As we will detail below, the authors omit mention of key aspects of our methodology and mischaracterize others. Several of the most significant purported shortcomings involve hypothetical events that “might be” true or are “likely.”
In Brief:
RAND: Scorecard misses many complications because it mainly counts events that occur after a patient leaves the hospital.
The basis of this assertion, a study which found large numbers of in-hospital complications for procedures like aortic resections, suggests that for low-risk procedures comparable to those included in Scorecard, more than 90 percent of complications are captured by tracking what happens after a patient leaves the hospital.
RAND: ProPublica erred when it held hospital quality constant when comparing surgeons.
The fairest way to compare surgeons is to level the playing field by evaluating them independently of the quality of the hospital where they operate. What RAND portrays as an error is a difference of opinion about the best way to compare surgeons. When patients search for a surgeon “near me,’’ Scorecard’s list of results is a combined ranking that includes hospital performance. The RAND authors omit this key piece of information.
RAND: Scorecard might call a surgeon ‘red’, ‘yellow’ or ‘green’ in the Scorecard, when they should be in one of the other categories.
Scorecard’s visualization shows red, yellow and green ranges for each procedure to let patients compare the performance of an individual surgeon to their peers nationwide. For each surgeon, Scorecard displays a shaded bar (a 95 percent confidence interval) projected against high, medium and low ranges of complications. If there is a strong possibility a surgeon could belong in more than one category, the visualization makes it clear.
RAND: Users cannot understand confidence intervals.
We user-tested Scorecard before launch, and ordinary people were able to understand how the confidence intervals worked even before we added explanation in the published version.
RAND: Scorecard does not take account of differences among surgeons’ patients.
Scorecard intentionally focused on simpler elective procedures with very low complication rates and patients that were generally healthy. Overall, 97 percent of patients in our analysis underwent surgery without dying or having to return to the hospital. Although patients in our data had various health problems and complexities, most surgeons were able to operate on them with few if any subsequent complications.
(If you are unfamiliar with RAND Corp., it is one of the country’s busiest think tanks. Though primarily focused on defense research, it also has a health policy arm. RAND is nonprofit and nonpartisan.)
Scholars can disagree with the choices we made in creating Surgeon Scorecard, and we welcome debate. But that conversation should be grounded in fact and evidence. RAND’s conclusion that patients should not use Surgeon Scorecard in picking a doctor should be taken for what it is — a mixture of opinion and conjecture.
We offer the following specific responses:
RAND: ProPublica is not measuring all complications, including those that happen during the initial surgical stay and those that result in outpatient treatment.
In designing Surgeon Scorecard, we set out to capture post-operative complications that were both serious health events and unlikely to be affected by subjective judgments. Our review of Medicare records showed that hospitals were not consistent in their reporting of mishaps that occurred during the initial admission. For that reason, we focused on records of two events on which there could be no dispute: Deaths and readmissions within 30 days. In doing this, we were following the lead of many other health care researchers.
RAND questions this approach, quoting a study stating that 67 percent of surgical complications occur during a patient’s initial hospital stay. This 2010 study, which was co-written by one of the RAND co-authors, looked at five procedures all but one of which are far more complicated than the routine, elective surgeries examined in Surgeon Scorecard. It is undoubtedly true that aortic resections and removal of the pancreas involve significant numbers of in-hospital complications. But suggesting the outcomes of these procedures are relevant to what happens after knee replacements or gall bladder removals strikes us as both illogical and unsupported by any evidence.
In the study’s one category of procedures with a comparable risk of complication to our elective surgeries, breast lumpectomies and mastectomies, 92.4 percent of complications occurred post discharge. By the RAND authors’ own logic, we are catching 9 out of 10 events, not 1 out of 3.
Here are some things we considered in defining a “complication” for Scorecard:
- We wanted to be conservative, only using the most reliable data available to researchers outside of protected medical records. RAND’s authors argue that Scorecard is deficient because it doesn’t rely on clinical data — detailed information from patients’ medical charts, notes and internal hospital recordkeeping systems. But such information is not publicly available, and there is no national database of clinical information, public or private. We didn’t neglect to use it — it doesn’t exist. When the authors argue for reporting that relies on clinical data, they are really arguing for no national reporting at all.
- We wanted to set a reasonably high bar for patient harm. Patient issues and complications that were quickly and easily resolved — i.e., not severe enough to result in death or a hospital readmission — are not part of Scorecard’s analysis. That is fair to surgeons and hospitals, and is in line with other studies and systems (Medicare, for one) that track readmissions and mortality as safety indicators.
- We wanted to provide patients with a single piece of information based on actual data about patient outcomes — and that went beyond the kind of star or letter grades that abound in consumer health care rating systems. We tried to avoid measures like “infections per thousand ventilator days” because they are confusing for a lay audience and because they mask the human toll of medical mishaps.
We learned from our own research, as well as studies by others, that accuracy varies in the billing records hospitals submit to Medicare. These records provide the patient-level diagnostic information Scorecard uses to compute surgeon complication rates. To address this variation, we based Surgeon Scorecard on the primary diagnosis and principal procedure codes, which must be accurate for a hospital’s Medicare claim to be paid.
To determine which readmissions we would count as complications, we asked panels of five or more medical experts — including surgeons — to review and rate the list of primary diagnosis codes. The experts identified which of these primary codes could reasonably be considered to arise as a result of one of our rated operations — that is, be a complication.
As the RAND authors point out, there are many ways to measure the outcomes of surgery. Did a knee patient regain full use of a leg, or did a prostatectomy patient’s cancer return? Such a list is almost inexhaustible and impractical as the subject for a safety scorecard.
Does the information in Surgeon Scorecard include all conceivable information about what happens to a patient during and after surgery? No, the same way information about a driver’s accidents doesn’t say everything about what kind of driver he or she is. But if a driver has had a lot of accidents — or a surgeon a lot of deaths and readmissions — they are potentially higher-risk. We think that’s information the public should know.
The RAND authors seem to argue that if you can’t tell patients everything, you shouldn’t tell them anything. In their view, it appears the most important goal of any rating system is to rank surgeons with certainty, from top to bottom, like sports teams. We agree that accuracy matters, but we are concerned primarily about the safety of patients. We think it’s essential to give patients the best information available to help them lessen the chance they will suffer serious medical harm. Reasonable people can disagree over how to strike this balance.
We are considering ways to measure the effect of in-hospital complications in future versions of Surgeon Scorecard. We already have begun working with medical centers, surgical groups and other experts to identify methods that might be useful and meet the criteria listed above.
RAND: “As currently constructed, the Scorecard masks hospital-to-hospital performance differences, thereby invalidating comparisons between surgeons in different hospitals … setting hospital random effects to 0 is a methodological decision with no good justification.”
First, this is a technical area, and we ask readers to bear with us. We spent many months wrestling with the best way to answer this question: In measuring a surgeon’s performance, what role does the hospital play? How much of a surgeon’s score is due to the team around her? We solicited advice from some of the most respected figures in the field.
Surgeon Scorecard takes into account a number of factors that could influence the surgeon’s rate of complications, including each patient’s age, complexity and gender. We then used a well-accepted statistical method (a hierarchical linear model) that measures the relative contributions of those factors in predicting a surgical complication.
Differences in hospital performance are one such factor. It is logical that the same surgeon working with a less-skilled hospital team could have a higher complication rate than if he operated with top-notch support. The statistics we used make it possible to measure both a hospital’s effect on a surgeon’s score and a surgeon’s score absent the hospital’s influence.
Contrary to what the RAND authors assert, there is a perfectly good reason for isolating a surgeon’s performance from a hospital. It is to level the playing fieldamongsurgeons. We held constant the effects of the hospital (and the patient pool) to assure, as much as possible, that surgeons’ scores were not dragged down by things beyond their control. We believe this is the best way to be fair to doctors who are, after all, the ones whose names appear in our database
We do agree with the RAND authors that the goal of being fair must be balanced with the goal of helping patients find the safest possible care. To this end, Scorecard does integrate hospital quality into search results when users look for surgeons “near me.” The search results return a ranking based on both individual complication rates and hospital effects.
To see this more clearly, we’ve reproduced a typical result a user might see if they search by geography (e.g. city, address, or ZIP code). Shown below is the result of a search for New York ZIP code 10013. The results in this screenshot are the surgeon-hospital combinations with lowest Adjusted Complication Rates (ACR), just as the RAND authors argue is important.
We explained the workings of the “near me” search twice to the RAND authors during our exchanges. It is unclear why they chose to omit any mention of it from their opinion piece. The RAND authors speculate that Scorecard might endanger patients by steering them to good surgeons at poor hospitals when they would be better off with mediocre surgeons at great hospitals. In fact, the Scorecard was designed to rank search results so that this should not happen.

RAND: “The Scorecard appears to have poor measurement reliability (i.e. it randomly misclassifies the performance of many surgeons) …”
First, let’s clarify what ‘misclassification’ actually means in this context: It is the possibility of assigning a surgeon to one color category (‘green’, ‘yellow’ or ‘red’), when their ‘true’ complication rate should place them in a different category.
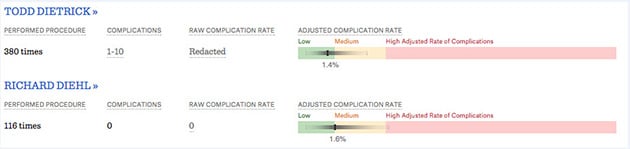
But this is a fundamental misstatement of how we presented the data. Surgeon Scorecard presents a surgeon’s “adjusted complication rate” not as a single point estimate, but within a range. This can be seen in the screenshot below, which is a comparison of two surgeons, performing the same operation, at the same hospital.
The green, yellow and red segments provide context, indicating what nationally is a low, medium or high rate of complications for this procedure.The surgeons themselves aren’t classified as green, yellow or red. Each surgeon’sACR — the particular point estimate — is surrounded by a 95 percent confidence interval, which is shaded to reflect probability concentration, as per best data visualization practices.
The “misclassification” alleged by the RAND authors does not exist because no classification occurs in the first place. To further bolster their point, the authors choose an edge case — one where a surgeon’s ACR range essentially straddles two zones. Placing Dr. Diehl’s ACR point estimate in the yellow range, they argue, misleads patients because there is substantial possibility that his true rate is in the green range.
Take a closer look at the screenshot below. Would patients really be shocked to learn there is some possibility that Dr. Diehl’s true complication rate is in green? We think not. Would it mislead doctors and other medical providers, the other primary audience for the Scorecard? Absolutely not.
RAND: “Producers can publish a report with high random misclassification rates, under the assumption that confidence intervals … will be understandable to the general public … Such efforts are likely to be futile, as most people assume that the data contained in a published report are reliable.”
The RAND authors argue that most users are “likely” not sophisticated enough to understand the confidence intervals around surgeon complication rates in Scorecard. They offer no direct evidence. The RAND authors have not user tested Scorecard with the general public. We have. Our testing found that users were able to interpret the visualization correctly — even without the explanatory aids we added to the final version. Medical providers clearly have the sophistication to interpret confidence intervals, and it’s essential that we report them for their accurate understanding of our analysis.
RAND: “… [T]he risk of misclassification is high; this problem can be addressed by using buffered benchmarks or similar direct approaches …”
What the RAND authors are describing is a classic tradeoff in statistics: false positives vs. false negatives. On the one hand, we might say a surgeon has a high complication rate when the ‘true’ rate is average (false positive). On the other hand, we might say surgeon is average when the ‘true’ rate is high (false negative).
As mentioned earlier, describing Scorecard as a “classification” scheme is erroneous. But it is, of course, possible that a surgeon’s “true” rate is at the outer edge of the range we depict. (Or, rarely, beyond — this is a 95 percent confidence interval). Consider this screenshot:

The 95 percent confidence intervals of all three surgeons overlap. If our only goal was to avoid false positives (i.e. calling Drs. Ronzo and Toumbis different from Bono, when their ‘true’ complication rates are really the same) we would report these doctors as identical.
This is often done in health care statistics, and we believe it doesn’t serve patients. If the results above related to hospitals, the Centers for Medicare & Medicaid Services would say all three were performing “as expected.” The use of a “buffered benchmark,” the other solution proposed by the RAND authors, would achieve a similar result.
But if, as in this example, it is more likely than not that the surgeons perform differently, then there is a much greater danger of the other error: portraying a low-performing surgeon as equivalent to a peer when, in fact, he is not. If we accept, for the sake of discussion, the RAND authors’ premise that consumers are not math literate, then how can we expect them to grasp that surgeons portrayed as the same are actually more likely to be different?
Here again we face a situation where reasonable people can disagree when weighing trade-offs and competing objectives. The RAND authors’ proposed solutions lower the possibility of mischaracterizing surgeons, but at the cost of concealing many likely differences. We felt it was more important to inform patients.
RAND: “The adequacy of the Scorecard’s case-mix adjustment is questionable. … A likely explanation is that ProPublica’s case-mix adjustment method fails to capture important patient risk factors. None of ProPublica’s methods accounts for the risk factors present in more-detailed surgical risk models derived from clinical data.”
As we wrote in our methodology — and RAND’s authors do not mention — Surgeon Scorecard measures performance on a set of common operations that are typically elective procedures. To be fair to surgeons, we deliberately chose to avoid operations that might involve complex cases or extremely sick patients. As such, the patient mix in our data is a relatively healthy population overall.
We excluded all emergency room admissions. We excluded all transfers into the hospital from a place like a nursing home. And we excluded any procedures performed because of unusual diagnoses. We spoke to surgeons who performed each operation to be sure we only included the bread-and-butter version of each procedure. Next, we risk-adjusted using the many diagnoses that are included in each record. We could see each patient’s age, gender and whether they suffered from things like diabetes, obesity, heart disease or other comorbidities that might make them more susceptible to a complication. The effects turned out to be small because our analysis found it possible to safely perform these procedures on patients with these perceived risk factors. Ninety-seven percent of the patients in our analysis left the hospital alive and were not readmitted, as one would expect for a routine procedure.
Our results show that Scorecard does not penalize surgeons who care for high-risk patients. Many surgeons in Scorecard have good scores even though they work in areas known for unhealthy populations. Likewise, there are many surgeons with good scores at hospitals known for taking on some of the toughest cases.
RAND: “The accuracy of the assignment of performance data to the correct surgeon in the ProPublica Surgeon Scorecard is questionable. … There is reason to suspect that these readily detectable misattributions are symptoms of more pervasive misattributions of surgeries to individual surgeons, and that these errors are still present in the Scorecard.”
As noted, the data in Surgeon Scorecard comes from billing claims that hospitals submit to Medicare (which is financed by taxpayers). In addition to information about the surgery and a patient’s health condition, the claims include a code that identifies the operating physician. It turns out that some hospitals submitted claims that listed physicians with inappropriate specialties, and even some non-physicians, as the operating surgeon.
After extensively screening the Scorecard data based on information in the government’s national registry, we found such misattributions affected less than one percent of the 2.3 million operations that were analyzed in Scorecard. They were mainly concentrated in a small number of hospitals. Just two hospitals accounted for more than 10 percent of the misattributed operations.
Out of an abundance of caution, after screening we removed all listings where there was any reasonable likelihood that misattributions were resulting in inaccurate results.
We removed physicians from Scorecard if a hospital they worked at misattributed more than 5 percent of claims in one of the procedures we analyzed, or if they misattributed more than 100 claims overall. We are working with Medicare and hospitals to resolve misattributions in our next update, and we think many of the surgeon results we have removed will prove to be accurate upon further investigation
Numerous surgeons and hospital officials across the country have told us Scorecard’s findings are consistent with their own internal records and experience. Surgeon Scorecard has been viewed more than 1.8 million times — about 5,000 times per day in recent weeks — with only a handful of complaints from physicians. We think that record speaks volumes about Scorecard’s validity and usefulness to patients.










