


Update (1/18/2011):We originally wrote that we had promising results with the commercial product deskUNPDF’s trial mode. We have since ordered the full version of deskUNPDF and tried using it on some of the latest payments data.
Adobe’s Portable Document Format is a great format for digital documents when it’s important to maintain the layout of the original format. However, it’s a document format and not a data format.
Unfortunately, it seems to be treated like a data transfer format, especially by some government agencies and others, who use it to release data that would be much more useful for journalists and researchers as a spreadsheet or even as a plain text file.
In our Dollars for Docs project, companies provided their data in PDF format.
Wikipedia has a good list of PDF tools and converters. However, we didn’t find a one-click-does-it-all solution for converting PDFs into spreadsheets while gathering the Dollars for Docs data.
We recently tested the commercial product deskUNPDF on several of the latest payment lists. In the vast majority of entries, deskUNPDF does an accurate conversion. But like the other methods described in this guide, it does not work perfectly for all the sets of data. For example, with the most recent Johnson & Johnson PDF, deskUNPDF omitted some of the text within some cells that contained long strings (like the names of the payees), This required us to manually verify each cell for accuracy.
Here are three other conversion methods we used for Dollars for Docs that involve a mix of software and coding. However, they still require some manual clean-up, which can be time-consuming for 50+ page documents.
Note: The following guide is for PDFs that actually have embedded text in them. Can you highlight the text to copy and paste it? Then this is the right guide. Otherwise, for PDFs that are secure, or PDFs that are essentially images of text – such as scanned documents, visit this tutorial.
Method 1: Third-Party Sites
Cometdocs and Zamzar are web-based services
that convert PDF files that you upload. After a short turnaround time, you’ll receive an e-mail with a download link (as well as an advertisement for their enterprise services).
We’ve had good results from CometDocs. For the Johnson & Johnson (Ortho-Mcneil-Janssen division) file, which you can download here, we still had to manually clean up entries that were split across several lines.
However, the mistakes in conversion can be more than superficial. For example, using CometDocs on the Eli Lilly PDF yielded this conversion:
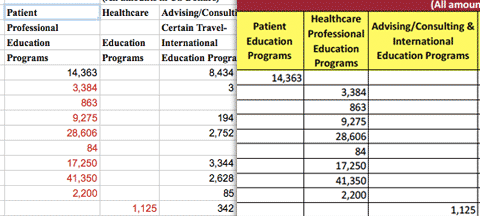
Right: The original PDF.
On this page, it appears that an entire column of numbers was shifted over. This is an error that would be difficult to catch without comparing the output to the original PDFs.
Method 2: Convert to HTML in Acrobat
As it turns out, Lilly’s PDF has some structure behind it, which we can take advantage of by converting the PDF to HTML. We don’t know of any free PDF to HTML tools, so hopefully your shop already has a copy of Adobe Acrobat Pro.
After downloading the Lilly report, open it with Acrobat. Then select Save As, then select HTML 3.2 as the format.
Optional programming
At this point, you are pretty much done. You can use your web browser to open up the gigantic HTML file that was just created, Select All, Copy, and then Paste into Excel. You’ll spend a little time deleting the header rows and finding anomalies, but Excel generally does a good job of automatically converting HTML tables into spreadsheet form.
With a little programming, you can parse through the file and do some cleanup at the same time (we go into more explanatory detail about the Ruby parsing library, Nokogiri, in the Flash and web scraping tutorials):
require 'rubygems'
require 'nokogiri'
#Open the file using the Nokogiri library
page = Nokogiri::HTML(open("EliLillyFacultyRegistryQ22010.html"))
#We use Nokogiri's css method to tell it we want all the table row elements:
rows = page.css('tr')
# rows is now an Array containing (use rows.length to find this out) 4,596 entries
# In this file, each row's first child element is <th>, with the rest being <td>
rows.each do |row|
# select the TH and TD elements within each TR
columns = row.css('td,th')
# the 'columns' array is now an array of the actual text within those elements
columns = columns.map{|t| t.text}
# Now join each element in the columns array with a tab-character, and then print it out as a line
puts columns.join("\t")
end
The above code will print out all the PDF contents, including the header row and narrative description text. So, assuming that actual data fits in a specified format (a table row with nine columns), we can alter the script to separate the rows into different files. Rows with three columns, for example, outputs to a file called ‘pdf-columns-3.txt’
When you do this, you’ll find that all valid data rows have nine columns. But there is one more issue with this particular PDF: some rows have each column value repeated twice:
So, for data rows in which there are nine columns, we can check to see if the third column (state initials) contains exactly two capital letters. If not, then the column has the duplicated-data error. In this special case, we can print the corrected data (by splitting the duplicated-data values in half) next to the erroneous columns and then go into a spreadsheet program to compare the results. Here is the code for the entire process:
require 'rubygems'
require 'nokogiri'
datarows_by_column_count = {}
Nokogiri::HTML(open("EliLillyFacultyRegistryQ22010.html")).css('tr').select{|row| !row.text.match(/2010 To Date Aggregate/) }.each_with_index do |row, line_number|
cols = row.css('th,td').map{|t| t.text.strip}
if cols.length == 9 # a valid data row
if !cols[2].match(/^[A-Z]{2}$/)
# if the state initial column does not contain exactly two capital leters
corrected_cols = []
cols.each_with_index do |col, index|
# populate corrected columns
nval = col
if index > 3 # from the fourth column on, the data is numerical. We need to strip non-numbers
nval.gsub!(/[^\d]/, '')
end
corrected_cols[index] = nval[0..(nval.length/2.0).ceil-1]
end
cols += corrected_cols
end
end # endif cols.length==9
datarows_by_column_count[cols.length] ||= [] # initialize a new array if it doesn't exist
datarows_by_column_count[cols.length] << ([line_number]+cols).join("\t")
end
# now print to files
datarows_by_column_count.each_pair do |column_count, datarows|
if datarows.length > 0
File.open("pdf-columns-#{column_count}.txt", 'w'){ |f|
f.puts(datarows)
}
end
end
Method 3: Convert to Text, Measure Column Widths
Unfortunately, not all PDF tables convert to nice HTML. Try the above method on the GSK file, for example. Converting it to HTML results in this mess:

One possible strategy is to analyze the whitespace between columns. This requires the use of regular expressions. If you don’t know about them, they’re worth learning. Even without programming experience, you’ll find regular expressions extremely useful when doing data cleaning or even advanced document searches.
The first step is to convert the PDF to plain text. You can use the aptly named pdftotext, which is part of the free xpdf package. We’re using a Mac to do this. Linux instructions are pretty similar. Under Windows, your best bet would be to use Cygwin.
For this example, we will use the GSK disclosure PDF, which you can download here.
pdftotext -layout hcp-fee-disclosure-2q-4q2009.pdf
This produces hcp-fee-disclosure-2q-4q2009.txt. The -layout flag preserves the spacing of the words as they were in the original PDF. This is what the GSK file looks like in text form:
Fees Paid to US Based Healthcare Professionals for Consulting & Speaking Services 1st Quarter through 3rd Quarter 2010 Health Care Professional Location Payee Name Consultant Speaker Total Fees Alario, Frank BAYVILLE, NJ Frank C Alario MD PC $6,500 $6,500 Alavi, Ali FULLERTON, CA Ali Alavi Consultant, LLC $41,000 $41,000 Alavi, Ali FULLERTON, CA Ali S Alavi $37,500 $37,500
Let’s look at the easiest scenario of text-handling, where every cell has a value:
Name State Travel Service Smith, Jon IA 100 200 Doe, Sara CA 200 0 Johnson, Brian NY 0 70
There’s no special character, such as a comma or tab, that defines where each column ends and begins.
However, values in separate columns appear to have two or more spaces separating them. So, we can just use our text editing program to find and replace those to a special character of our choosing.
Regular expressions allow us to specify a match of something like “one space or more.” In this case, we want to convert every set of two-or-more consecutive spaces into a pipe character (“|”).
Many major text-editors allow the use of regular expressions. We use TextMate. For Mac users, TextWrangler is a great free text editor that supports find-and-replace operations with regular expressions. Notepad++ is a free Windows text-editor; here’s a tutorial on how to use regular expressions in it.
In regular expression syntax, curly brackets {x,y} denote a range between x and y occurrences of the character preceding the brackets. So e{1,2} will match 1 to 2 ‘e’ characters. So the regular expression to find “bet” and “beet” is: be{1,2}t.
Leaving off the second number, as in e{1,}, means we want to match at least one ‘e’, and any number of that character thereafter. So, to capture two-or-more whitespaces, we simply do: “ {2,}“.
So entering ” {2,}” into the “Find:” field and “|” into “Replace:”, we get:
Name|State|Travel|Service| Smith, Jon|IA|100|200 Doe, Sara|CA|200|0 Johnson, Brian|NY|0|70
Easy enough. But a common problem is when a cell is left blank. This causes two empty columns to be seen as just one empty column, according to our regular expression:
Name State Travel Service Smith, Jon IA Doe, Sara CA 0 Johnson, Brian 0 70
Name|State|Travel|Service| Smith, Jon|IA Doe, Sara|CA|0 Johnson, Brian|0|70
If you’ve worked with older textfile databases or mainframe output, you probably have come across tables with fixed-width columns, where the boundaries of columns is a pre-determined length.
Looking at the above table, we can see that even if there are blanks in the column, the actual data falls within a certain space. So, using regular expressions with a little Ruby scripting, we can programatically determine these columns.
We first delimit each row with the ” {2,}” regular expression. As we saw in the example above, we’ll end up with lines of varying number of columns.
If we then iterate through each column and find the farthest-left and the farthest-right position per column on the page, according to each word’s position and length, we should be able to produce on-the-fly a fixed-width format for this table.
This is easier to explain with a diagram. Here’s a sparsely populated table of four columns.
1: Banana Currant 2: Alaska Colorado Delaware 3: Bear
If we delimit the above with ” {2,}”, we’ll find that the first row will have 2 columns; the second row, 3 columns; and the third, 1 column.
Programmatically, we’re going to store each of these lines of text as an array, so Row_1 would be [“Banana”, “Current”], for instance. This is just an intermediary step, though. What we really want is where each word begins and ends on that line. If the very first position is 0, then “Banana” begins at position 13 and ends at position 19, that is, 19 spaces from the beginning of the line. Doing this for each line gets us:
1: [13,19](Banana), [24,31](Currant) 2: [4,10](Alaska), [24,33](Colorado), [36,44](Delaware) 3: [14,18](Bear)
So as we read the values for each line, let’s keep a master list of the farthest-left and farthest-right positions of each column.
Reading through the first line, this list will be: [13,19], [24,31], where “Banana” and “Currant” are positioned, respectively.
When our script reads through the second line, it finds a word (Alaska) at position 4 and ending at 10.
Since it ends before the starting position (10 < 13) of what the program previously thought was the starting boundary of the first column, it stands to reason that the space containing “Alaska” is actually the table’s first column.
When the script reads “Colorado”, it sees that it intersects with “Currant”‘s position in the first line. It assumes that the two share the same column (now the third), and changes the definition of that column from [24,31] to [24,33], since “Colorado” is a slightly longer word.
The list of columns is now: [4,10], [13,19], [24,33], [36,44].
In the third line, the only word is “Bear” and its dimensions fall within the previously defined second column’s positions [13,19]
So now with our master list of positions, we can read each line again and break it apart by these column definitions, getting us a four-column table as expected.
Splitting the PDF
When converting the PDF to text, sometimes the columns won’t be positioned the same across every page. So let’s begin by splitting the PDF into separate pages by calling pdftotext within Ruby:
for page_num in 1..last_page_number
`pdftotext -f #{page_num} -l #{page_num} -layout #{the_pdf_filename} "#{the_pdf_filename.gsub(/\.pdf/i, '')}_#{page_num}.txt"`
end
And then iterate through each page to calculate its fixed-width format with the algorithm described above. Here’s the commented code for the entire program:
##
## Note: Run this script from the command line. i.e., "ruby thisscript.rb FILENAME NUMPAGES MIN_COLS LINES_TO_SKIP"
##
require 'fileutils'
class Object
def blank?
respond_to?(:empty?) ? empty? : !self; end; end
# filename = name of the PDF file, that will be broken into individual txt files
# number_of_pages = number of pages in the PDF
# min_cols = the minimum number of columns, when delimited by \s{2,}, that a line should have before taking into account its column spacing. Setting it to at least 2 or 3 eliminates lines that were mistranslated.
# lines_to_skip = the number of non-data header lines to skip per page. Should be the same per page, usually.
if ARGV.length < 4
puts "Call format: ruby spacer.rb PDF_FILENAME NUMBER_OF_PAGES_IN_PDF MINIMUM_NUMBER_OF_COLUMNS_PER_LINE NUMBER_OF_HEADER_LINES_TO_SKIP"
puts "i.e. ruby spacer.rb `pdftest.pdf` 42 4 3"
raise "Please specify all the parameters"
end
filename = ARGV.first
number_of_pages, min_cols, lines_to_skip = ARGV[1..-1].map{|a| a.to_i}
filedir = File.basename(filename).gsub(/[^\w]/, '_')
puts "Filename: #{filename}, #{number_of_pages} pages, minimum of #{min_cols} columns, and skip #{lines_to_skip} lines per page"
FileUtils.makedirs(filedir)
compiled_file = File.open("#{filedir}/compiled.txt", 'w')
for page_num in 1..number_of_pages
new_f_name = "#{filedir}/#{filename.gsub(/\.pdf/i, '')}_#{page_num}.txt"
`pdftotext -f #{page_num} -l #{page_num} -layout #{filename} "#{new_f_name}"`
puts "#{new_f_name} created"
pdf_text = File.open(new_f_name).readlines[lines_to_skip..-1]
puts "Opening #{new_f_name} (#{pdf_text.length} lines)"
master_column_position_list = []
pdf_text.each_with_index do |line, line_number|
current_line_pos = 0
columns = line.strip.split(/ {2,}/).map{|col| col.strip}
if columns.length > min_cols
columns.each_with_index do |column, col_index|
# find the position of the word, starting from current_line_pos
col_start = line.index(column, current_line_pos)
# update current_line_pos so that in the next iteration, 'index' starts *after* the current word
current_line_pos = col_start + column.length
# temp variable for easier reading; this is where the current word begins and ends on the line
this_col_pos = [col_start, current_line_pos]
# with each column-word, find its spot according to the positions we've already found in master_column_position_list
# (There's probably a more efficient way than iterating from the beginning of the master-list each time, but there's only 2-12 columns at most...)
if master_column_position_list.length == 0
master_column_position_list.push(this_col_pos)
else
master_column_position_list.each_with_index do |master_col_pos, m_index|
# check to see if current column-word is positioned BEFORE the current element in master_column_position_list. This happens when the END of the column-word is less than the BEGINNING of the current master-list element
if master_col_pos[0] > this_col_pos[1]
# push new position before the current index in the master-list
master_column_position_list.insert(m_index, this_col_pos)
break;
# if the column-word's BEGINNING position is after the END of the current master-list position, then iterate unto
# the next element in the master-list. Unless we are already at the end; if so, push this column-word onto the array
elsif master_col_pos[1] < this_col_pos[0]
if m_index == master_column_position_list.length-1
master_column_position_list.push(this_col_pos)
break;
end
else
## If there is any overlap in the columns, merge the two positions, taking the minimum of the starting positions and the maximum of the ending positions
# elsif master_col_pos[0] <= this_col_pos[1] && master_col_pos[1] >= this_col_pos[0]
master_col_pos[0]= [master_col_pos[0], this_col_pos[0]].min
master_col_pos[1]= [master_col_pos[1], this_col_pos[1]].max
break;
end
end
# end of iterating through master_column_position_list
end
# end of if master_column_position_list.length == 0
end
# end of iterating through each column.each_With_index
end
# end of unless line.strip.blank?
end
# end of each line iteration
puts "Master positions for page #{new_f_name}: \n#{master_column_position_list.map{|mpos| "(#{mpos.join(',')})" }.join(', ')}\n\n"
# Now create new text_file. We map each position in master_column_position_list onto each line, creating a substring for each element that exists in the master-list. We also prepend the current page number, line number, and the number of columns, for later diagonstics
pdf_text.each_with_index do |line, line_number|
unless line.strip.blank?
compiled_file.puts( ([page_num, line_number, master_column_position_list.length] + master_column_position_list.map{|pos| line[(pos[0])..(pos[1])].to_s.strip}).join("\t"))
end
end
end
# end of each page # iteration
compiled_file.close
You’ll note that in the section where we output the results to compiled_file, we’ve also included the page number, line number, and number of columns in that page. When we try this program on Lilly’s PDF, there are some columns in which the data is spread out enough to be considered separate columns by our program. So keeping track of the columns found per page allows us to quickly identify problem pages and fix them manually.

PDF-to-Text Anomalies
Almost every conversion ends up with some strange artifacts. For example, in the above conversion of the GSK document, we get some entries in the last column that are repeated over several lines.
I don’t know enough about how PDFs are generated to prevent this. But after any conversion, you’ll need to use Excel, Google Refine, or some custom code to check that all the fields have values in an expected range.
Regular expressions are pretty much essential to this, allowing you to determine which cells don’t fit a certain format, such as an exact length of characters, or a currency format like $xx,xxx.00.
Conclusions
There is no single method we could find that does PDF translation perfectly. We recommend trying one of the web services first. If the result isn’t as accurate as you like, it’s not too much work to write some text-processing code.
With any method, you may end up spending lots of time cleaning up the occasionally mistranslated cell, but at least it won’t be as arduous as manually retyping the entire PDF.
The Dollars for Docs Data Guides
Introduction: The Coder’s Cause – Public records gathering as a programming challenge.
- Using Google Refine to Clean Messy Data – Google Refine, which is downloadable software, can quickly sort and reconcile the imperfections in real-world data.
- Reading Data from Flash Sites – Use Firefox’s Firebug plugin to discover and capture raw data sent to your browser.
- Parsing PDFs – Convert made-for-printer documents into usable spreadsheets with third-party sites or command-line utilities and some Ruby scripting.
- Scraping HTML – Write Ruby code to traverse a website and copy the data you need.
- Getting Text Out of an Image-only PDF – Use a specialized graphics library to break apart and analyze each piece of a spreadsheet contained in an image file (such as a scanned document).








